-
Sora爆火48小时,大佬们怎么看?
本文来自微信公众号: 智东西(ID:zhidxcom) ,作者:程茜、ZeR0,编辑:心缘,原文标题:《Sora爆火48小时:杨立昆揭秘论文,参数量或仅30亿》,题图来自:视觉中国 OpenAI新爆款Sora的热度持续发酵,在科技圈的刷屏阵仗都快赶上正月初五迎财神了。 智东西2月17日报道,这两天,OpenAI首款文生视频大模型Sora以黑马之姿占据AI领域话题中心,马斯克、杨立昆、贾扬清、Jim Fan、谢赛宁、周鸿祎、李志飞等科技人物纷纷下场评论,一些视频、影视、营销从业者也关注起这个新工具,开始担心自己的饭碗。 OpenAI CEO萨姆·阿尔特曼在社交平台X上积极与网友互动,马斯克感叹“人类愿赌服输”,360集团创始人、董事长兼CEO周鸿祎预言“AGI实现将从10年缩短到1年”。身为竞争对手的AI文生视频创企Runway联合创始人兼CEO Cristóbal Valenzuela也被惊到发表感言。 技术大牛们则开动脑力,从有限资料中抽丝剥茧,推演Sora的技术配方。Meta首席AI科学家杨立昆称,纽约大学助理教授谢赛宁作为一作的扩散Transformer论文是Sora的基础。谢赛宁也积极发长文分析Sora基于DiT架构、可能用到谷歌NaViT技术,推算Sora参数量约30亿。 一些OpenAI技术人员还在持续放出更多用Sora生成的视频作品,如海上自行车比赛、男人向巨型猫王鞠躬、鲨鱼跳出海面吓到在海滩的人…… 民间高手们同样行动力惊人:有的将OpenAI展示的生成视频示例的提示词输入到Midjourney、Pika、RunwayML、Make-A-Video等其他明星模型对比效果;有的把Sora和比它早几个小时发布的谷歌最新力作Gemini 1.5 Pro玩起了联动。 Sora的爆火,再度坐实了阿尔特曼“营销大师”的称号。 一些网友怀疑阿尔特曼是专挑谷歌发Gemini 1.5的时间亮出Sora,硬生生把手握100万tokens技术突破的Gemini 1.5话题度杀到片甲不留,是一出用大型广告秀吸引更多融资的高招。 而最新被曝出的消息,似乎印证了OpenAI对新融资的迫切。据外媒报道,随着新一笔要约收购交易完成,OpenAI的估值或超过800亿美元。 阿尔特曼宏大的7万亿美元芯片筹资计划也亟待输血,毕竟最近刚给他的小目标再加1万亿美元,并收获了马斯克的评论。 这样看来,利好的还是AI infra和芯片企业。 一、大佬们怎么看Sora? 不管是震惊Sora的强大,还是吐槽其生成视频的破绽,都能收获极高的关注度。大佬们也分为几派,从不同角度对Sora进行点评。 1. 吃瓜感慨派:时间不等人,甘拜AI下风 代表之一是马斯克,在社交平台X上的各网友评论区活跃蹦跶,四处留下“人类愿赌服输(gg humans)”“人类借助AI之力将创造出卓越作品”等只言片语。 AI文生视频创企Runway联合创始人兼CEO Cristóbal Valenzuela感慨后浪拍前浪,以前需要花费一年的进展,变成了几个月就能实现,又变成了几天、几小时。 出门问问创始人李志飞在朋友圈感叹:“LLM ChatGPT是虚拟思维世界的模拟器,以LLM为基础的视频生成模型Sora是物理世界的模拟器,物理和虚拟世界都被建模和模拟了,到底什么是现实?” 2. 展望预言派:OpenAI还有武器,创企压力倍增 周鸿祎发了一条长微博和一个视频,预言Sora“可能给广告业、电影预告片、短视频行业带来巨大的颠覆,但它不一定那么快击败TikTok,更可能成为TikTok的创作工具”,认为OpenAI“手里的武器并没有全拿出来”“中国跟美国的AI差距可能还在加大”“AGI不是10年20年的问题,可能一两年很快就可以实现”。 美国旧金山早期投资人Zak Kukoff预测:一个不到5人的团队将在5年内用文生视频模型和非工会的劳动力。制作一部票房收入超过5000万美元的电影。 GitHub Copilot主创Alex Graveley则替生成式AI创企们捏了把汗:“如果OpenAI打算继续逐个行业地蚕食AI初创公司,他们应该尽快上市。构建一个只有500人受益的新经济是个糟糕的未来。” 前阿里副总裁、正在AI infra赛道创业的贾扬清,评价简单粗暴:“真的非常牛。”他认为“对标OpenAI的公司有一波被其他大厂fomo(害怕错过)收购的机会”“开源还需要一段时间才能catch up”,算法小厂“要不就算法上媲美OpenAI,要不就垂直领域深耕应用,要不就开源”,并预言“infra的需求继续会猛增”。 3. 上手体验派:比较多个视频生成模型,联动Sora和Gemini 1.5 知名连续创业者Gabor Cselle在测试关于美丽东京白雪皑皑的提示词后,得出的结论是Sora在长镜头上表现得更好。 Gabor Cselle还让谷歌Gemini 1.5 Pro观看并分析评论了OpenAI Sora制作的视频。 Sora的原提示词是:“美丽、白雪皑皑的东京市熙熙攘攘。镜头穿过熙熙攘攘的城市街道,跟随几个人享受美丽的雪天,在附近摊位上购物。绚丽的樱花花瓣随雪花在风中飞舞。” Gemini 1.5 Pro给出的评论是:“这段视频拍摄的是日本一条下雪的街道,樱花盛开。有一些不一致的地方表明视频可能是AI生成的。首先,雪下得很大,但樱花还在盛开,樱花通常开在春天,那时天气温暖,没有雪;其次,雪以一种很均匀的方式落下,这与现实生活中的雪通常不同;第三,尽管下着雪,视频中的人没有穿任何冬天的衣服。总的来说,这段视频在视觉上很吸引人,但前后矛盾之处表明这不是真实场景。” 4. 技术分析派:Sora或有30亿参数,基础论文被扒 含金量最高的当属围绕Sora核心技术的讨论。 PyTorch创始人Soumith Chintala从视频推测Sora是由游戏引擎驱动的,并为游戏引擎生成组件和参数。 英伟达高级研究科学家Jim Fan评价Sora是“视频生成的GPT-3时刻”“数据驱动的物理引擎”,认为它通过一些去噪、梯度下降去学习复杂渲染、“直觉”物理、长镜头推理和语义基础等。 多伦多大学计算机科学AI助理教授Animesh Garg夸赞OpenAI做得好,评价Sora像是“模型质量的飞跃,它不需要快速的工程来实现随时间一致的RTX渲染质量生成”。 纽约大学助理教授谢赛宁高赞Sora是“难以置信的、将重塑视频生成社区”,并发表多篇推文进行分析,推测Sora建立在扩散Transformer模型之上,整个Sora模型可能有30亿个参数。 值得一提的是,Meta首席AI科学家杨立昆转发评论称他的前同事谢赛宁和他的前伯克利学生、现任OpenAI工程师的William Peebles前年合著的扩散Transformer论文,显然是Sora的基础。 论文地址:arxiv.org/abs/2212.09748 杨立昆还特意指出,这篇论文曾因“缺乏新颖性”而被计算机视觉学术顶会之一拒收。 下一章将附上大牛们更全面的技术分析。 二、每个视频都能挑出错,Sora为什么还能这么火? OpenAI在发布Sora的博客文章下方特意强调其展示的所有视频示例均由Sora生成。比起OpenAI的承诺,更能证明Sora清白的是这些视频中出现的各种生成式AI“灵魂错误”。 比如,随着时间推移,有的人物、动物或物品会消失、变形或者生出分身;或者出现一些违背物理常识的闹鬼画面,像穿过篮筐的篮球、悬浮移动的椅子。 这些怪诞的镜头,说明Sora虽然能力惊人,但水平还不够“封神”。这也给它的竞品和担心工作被取代的人类留下了进化的余地。 毕竟,AI视频生成已经断断续续火了一年多,而当前最晚出场的Sora,就算是错漏百出,也已经在时长、逼真度等方面甩开同行一条街。 主要视频生成模型/技术对比(来源:东吴证券) 让机器生成视频,难点在于“逼真”。比如一个人在同一个视频里的长焦和短焦镜头里外观不会变化;随着镜头转动,站在山崖上的小狗应该跟山崖保持一致的移动;咬一口面包,面包就会少一块并出现牙印……这些逻辑对人来说似乎显而易见,但AI模型很难领悟到前一帧和后一帧画面之间的各种逻辑和关联。 首先要强调下生成式AI模型跟传统信息检索的区别。传统检索是按图索骥,从数据库固定位置调取信息,准确度高,但不具备举一反三的能力。而生成式AI模型不会去记住数据本身,而是从大量数据中去学习和掌握生成语言、图像或视频的某种方法,产生难以解释的“涌现”能力。 OpenAI在技术报告里总结了一些以前模型常用的视频生成和建模方法,包括循环网络、生成式对抗网络、自回归Transformer和扩散模型。它们只能生成固定尺寸、时长较短的视频。 而Sora实现了将Transformer和扩散模型结合的创新,首先将不同类型的视觉数据转换成统一的视觉数据表示(视觉patch),然后将原始视频压缩到一个低维潜在空间,并将视觉表示分解成时空patch(相当于Transformer token),让Sora在这个潜在空间里进行训练并生成视频。 接着做加噪去噪,输入噪声patch后Sora通过预测原始“干净”patch来生成视频。OpenAI发现训练计算量越大,样本质量就会越高,特别是经过大规模训练后,Sora展现出模拟现实世界某些属性的“涌现”能力。 这也是为啥OpenAI把视频生成模型称作“世界模拟器”,并总结说持续扩展视频模型是一条模拟物理和数字世界的希望之路。 令技术大牛们兴奋的焦点就在这个能力上。 扩散Transformer模型论文第一作者谢赛宁发表了多篇推文,分享对Sora技术报告的看法: 先看架构,构建于扩散Transformer(DiT)模型上,DiT=[VAE编码器+ ViT + DDPM + VAE解码器]。 其次是视频压缩网络,看起来只是一个训练原始视频数据的VAE(一个ConvNet),Token化可能在获得良好的时间一致性方面发挥重要作用。 谢赛宁回顾说,在研究DiT项目时,他和Bill没有创造“新颖性”,而是优先考虑了简单和可扩展性。 简单意味着灵活。他认为人们经常忽略掉一件很酷的事,当涉及到处理输入数据时,如果让模型方式更灵活。例如在MAE中,ViT帮助我们只处理可见patches,而忽略掩码patches;类似的,Sora“可通过在适当大小的网格中安排随机初始化的patches来控制生成视频的大小”,而UNet并不直接提供这种灵活性。 他猜测Sora可能还会使用谷歌的Patch n’ Pack(NaViT),使DiT适应各种分辨率/持续时间/宽高比。 论文地址:arxiv.org/abs/2212.09748 可扩展性是DiT论文的核心主题。就每Flop的时钟时间而言,优化的DiT比UNet运行得快得多。更重要的是,Sora证明了Dil扩展定律不仅适用于图像,也适用于视频——Sora复制了在DiT中观察到的视觉扩展行为。 谢赛宁推测在Sora报告中,第一个视频的质量相当糟糕,怀疑它使用的是基本模型尺寸,并做了个粗略计算:DiT XL/2是B/2模型的5倍GFLOPs,所以最终的16X计算模型可能是DiT-XL模型大小的3倍,这意味着Sora可能有大约30亿个参数——如果是真的,这不是一个不合理的模型大小。这可能表明,训练Sora模型可能不需要像人们预期的那样多的GPU——预计会有非常快的迭代。 在他看来,关键的收获来自“新兴的模拟能力”部分。在Sora之前,我们并不清楚长期的一致性能否独立出现,或者它是否需要复杂的主题驱动生成流水线,甚至是物理模拟器。OpenAl已经证明,虽然不完美,但这些行为可以通过端到端训练来实现。但还有两个要点尚未讨论: 1. 训练数据:完全没有谈论训练来源和构建,这可能只是暗示数据可能是Sora成功的最关键因素。 2. (自回归)长视频生成:Sora的一个重大突破是能够生成非常长的视频。制作2秒视频和1分钟视频的区别是巨大的。 在Sora中,这可能是通过允许自回归采样的联合帧预测来实现的,但一个主要挑战是如何解决误差积累并保持质量/一致性。一个非常长的(和双向的)条件作用环境?或者扩大规模可以简单地减轻这个问题?谢赛宁认为这些技术细节可能非常重要,希望在未来能被揭开神秘面纱。…
-
Sora爆火!人工智能将如何影响世界?
清澈灵动的眼眸、活泼可爱的萌宠、神秘莫测的海底世界、熙熙攘攘的夏日街区、充满科技感的魔幻都市…… 这段场景逼真、色彩丰富、氛围浓厚的短视频,全部由人工智能系统制作生成。 近日,美国开放人工智能研究中心OpenAI发布首个视频生成模型“Sora”。该模型通过接收文本指令,即可生成60秒的短视频。 而一年前,同样是这家研究中心发布的AI语言模型ChatGPT,让文本撰写和创作、检查代码程序等都变得易如反掌。 AI聊天、AI绘画、AI音乐……随着一系列AIGC(利用人工智能技术生成内容) 相继问世,让众人直言对现代社会生活产生颠覆性影响的“AI革命”正式来临。 AI究竟有哪些“本领”?为何它每一次迭代升级都能引发全球热议? 生成式AI可将输入内容 变成小说、 电影、艺术作品 谷歌公司旗下的人 工智能模型 “巴德”,可以根据你输入的多个词语迅速生成一篇短篇小说或诗歌。 今年2月,谷歌公司宣布“巴德”更名为“双子座”(Gemini)。这是一款多模态大模型,可理解和组合文本、代码、音频、图像和视频等不同类型的信息。 “巴德”用几个月的时间阅读互联网上几乎所有内容,并开发大语言模型,给出的答案就来自语言模型而并非网络搜索。 DALL-E 可以把你输入的任何内容变成艺术作品。 为了训练DALL-E,研发公司为它提供了约6亿张来自互联网的标签图片。 通过深度学习,它不仅可以理解单个物体,还可以学习不同物体之间的关系。 利用Runway , 你在几秒钟内就能生成平时需要数日才能完成的视觉效果。 该公司创始人巴伦苏埃拉直言,有了生成式AI的加持,未来电影制作的门槛和成本将大大降低。 生物医疗、无人驾驶、气象预报…… AI技术市场规模巨大 除了在艺术创作领域,AI技术在医药领域、城市服务、气象预告的应用也十分值得关注。 1月29日,美国知名企业家马斯克表示,他旗下的脑机接口公司“神经连接”完成首例脑机接口设备人体移植,移植者状态良好。据悉,这项技术是完全可植入的,由电池供电且是无线,全程通过蓝牙连接。 清华大学官网1月30日发布消息,该校医学院脑机接口研究团队与首都医科大学宣武医院联合,于2023年10月成功进行全球首例无线微创脑机接口临床试验。 这位因车祸造成脊髓损伤、四肢瘫痪14年的患者,经术后三个月康复训练,已实现自主喝水等脑控功能,抓握准确率超过90%。 虽然脑机接口技术依旧面临许多挑战甚至质疑,但毋庸置疑的是,人工智能在医疗领域,特别是根据医学影像进行诊断方面取得显著成就。目前,美国食品和药物管理局已批准约420种涉及成像的算法,主要用于癌症治疗。这些算法的准确率可达80%至90%。 除了医学领域,生成式AI也将更广泛参与到城市公共服务、气象预报实践中。 库马尔是印度的一名卡车司机。他在高速公路跑车时,一个往返就是60小时,长时间疲劳驾驶很容易发生交通事故。如今,他的工作旅途中多了一个“不会说话”的小伙伴,随时提醒他避免疲劳或注意车距。 这是一台集合AI和计算机视觉驱动技术的终端设备。 朝向外的摄像头可以测算车辆和其他物体间的距离关系。朝向司机的摄像头则会监控司机的行为和状态,如果司机打电话或者昏昏欲睡,设备就会提醒司机注意正确驾驶。 2023年7月,华为云盘古气象大模型正式上线欧洲中期天气预报官网 ,让世界看到中国大模型破解气象领域难题的能力。 世界银行估计,改进天气预报和早期预警系统每年不仅可带来价值1620亿美元的收益,还可以挽救约23000人的生命。 此外,目前AI人工智能在促进教育公平,应对老龄化社会方面也发挥着越来越重要的作用并形成巨大的市场规模。据彭博社预计,生成式AI的市场规模将在2032年扩大至1.3万亿美元。 AI生成欺骗性内容 干扰选举 或在国家大选期间制造混乱 AI技术带来许多新机遇的同时,也不可避免造成前所未有的挑战和隐患。其中,人工智能生成欺骗性内容干扰选举被认为是全球面临的重要挑战。 当地时间1月23日,2024年美国总统选举共和党党内初选在新罕布什尔州举行。在此之前,很多美国选民都表示,自己接到一通“来自美国总统拜登的电话”。 这通电话以拜登的口头禅“真是一派胡言”开头,建议选民不要给特朗普投票,而是把选票留到11月大选时投给民主党。随后,白宫新闻秘书皮埃尔澄清说,这是一则伪造的电话录音。 分析人士担心,在美国选民容易受到错误信息影响的当下,人工智能可能会在大选期间制造出更多混乱。 据不完全统计,2024年全球将有70多个国家或地区举行重要选举,覆盖超过全球半数人口。在刚闭幕的第60届慕尼黑安全会议上,全球多家科技企业就签署协议,承诺将在2024年打击旨在干扰选举的人工智能滥用行为。 人工智能的应用方式 要充分遵守伦理规则 工业和信息化部赛迪研究院数据显示,2023年,我国生成式人工智能的企业采用率已达15%,市场规模约为14.4万亿元。制造业、零售业、电信行业和医疗健康等四大行业的生成式人工智能技术的采用率均取得较快增长。 专家预测,2035年生成式人工智能有望为全球贡献近90万亿元的经济价值,其中我国将突破30万亿元,占比超过四成。 如何看待未来人工智能的发展? 中国互联网协会副理事长、伏羲智库创始人李晓东分析,人工智能经历六七十年的发展,目前被广泛应用到科技创新、文化产业和工业制造等领域。算力提升和成本降低,也让通用人工智能来到普通百姓的身边。 可以预见在不久的将来,人工智能将无处不在,推动信息化技能从数字化、网络化,全面进入到智能化时代。 “很快我们将不再讨论人工智能,因为人工智能已经融入到生活中,无处不在。”李晓东说。 从某种意义上讲,对人工智能的利用将会在国家之间、机构之间,甚至包括人与人之间形成新的代差和新的数字鸿沟,并推动人类从农业文明、工业文明走向数字文明。因此 能否充分学习和利用人工智能会对人类产生分化,甚至对人类文明产生巨大影响。 AI快速发展,监管将面临哪些挑战? 李晓东表示,“ 数据获取+应用方式”是AI监管的两大问题。 合理合法获取数据对人工智能至关重要,人工智能的应用方式也要充分遵守伦理规则。这 两个核心问题如果处理不当,将会严重影响人工智能的发展和利用。 从数据获取方面看 ,采集和获取不仅涉及到数据的产权问题,还涉及到国家安全和个人隐私。 如何合理合法获取数据,对于人工智能至关重要。 此外, 如何有效联通数据故障,促进数据交换共享,提升数据之间的互操作能力也是人工智能的治理重点。否则,没有持续数据支撑的人工智能发展将会严重受损。 从人工智能的应用方式来看 , 人工智能以前所未有的方式展现其强大的信息处理能 力,其本质是提升人类对信息的利用效率和效果。而人类社会有其基于特定国家和文化的法律法规和道德约束,人工智能发展也要充分遵从法律法规和道德伦理。 目前,部分人工智能技术确实对传统道德伦理及既定法律法规产生冲击,并产生全球性新的伦理规范和规则。 而在规则规范形成过程中,要保持积极互动跟踪,推动伦理规范和全球规则朝着向上的轨道前行。 ▌ 本文来源:央视新闻微信公众号(ID:cctvnewscenter) 监制/李浙 主编/马文佳编辑/马玮璐 校对/高少卓 部分图片/视觉中国 ©央视新闻
-
Sora爆火!上海交大天才少年是发明者之一?回应来了……
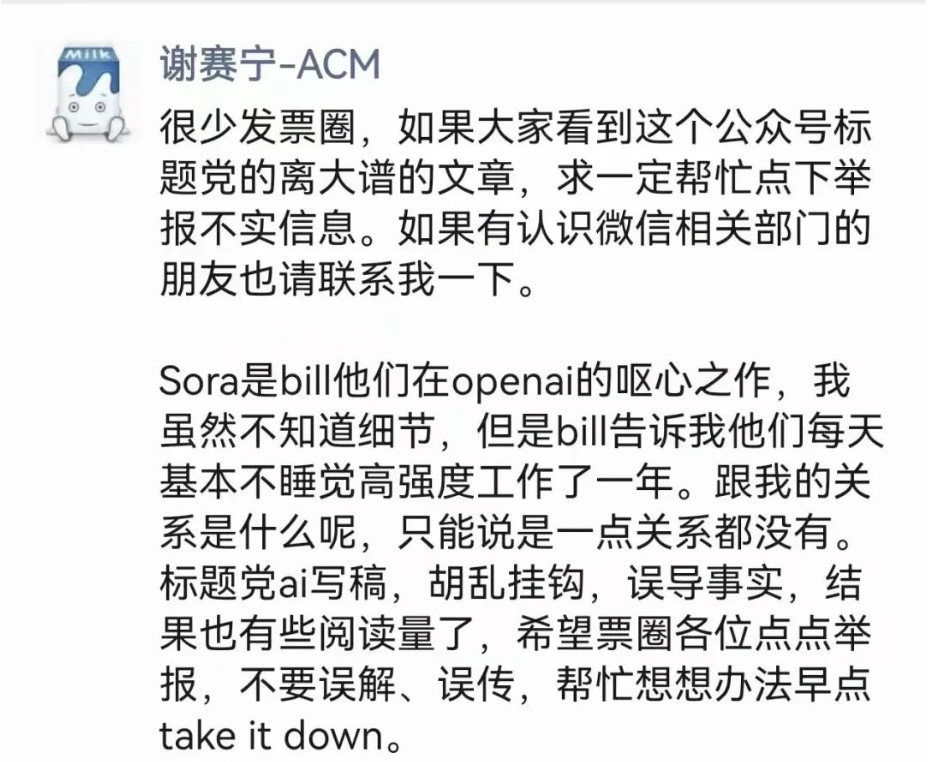
在刚刚过去的假期里,OpenAI发布的Sora成了全球人工智能领域的热门话题,但随之刷屏的是一篇名为《震惊世界的Sora发明者之一,是毕业于上海交大的天才少年——谢赛宁》的文章,文章提到曾经的上海交大ACM班成员谢赛宁是Sora的发明者之一。 文章一经发布就有了“可观”的阅读量,并得到大量转发。 据文汇报报道,仅仅一天,谢赛宁就在自己的微信朋友圈发布澄清声明,表示自己和Sora并没有关系。 但是他也谈到,对于Sora这样的复杂系统,人才第一,数据第二,算力第三,其他都没有什么是不可替代的—— 截图来源:文汇报 网友评论 据谢赛宁个人主页及上海交通大学校友会介绍,谢赛宁现任纽约大学报计算机科学助理教授,同时隶属于纽约大学数据科学中心。2013年,他从上海交通大学计算机科学与技术专业(ACM试点班)本科毕业。 AI生成视频效果“炸裂” 就在2月16日,OpenAI宣布推出全新的生成式人工智能模型“Sora”。据了解,通过文本指令,Sora可以直接输出长达60秒的视频,并且包含高度细致的背景、复杂的多角度镜头,以及富有情感的多个角色。 这意味着,继文本、图像之后,OpenAI将其先进的AI技术拓展到了视频领域。OpenAI亦表示,Sora是能够理解和模拟现实世界的模型的基础,这一能力将是实现AGI(通用人工智能)的重要里程碑。 Sora根据提示词生成的视频画面截图。图片来源:OpenAI官网 据中国新闻网报道,有专业人士表示,Sora是给内容创作者的超级大礼包,不仅可以降低成本、加速创作,还能让观众的视觉体验丰富到爆表。AI未来的画卷,将比我们想象的还要精彩。 也有声音认为,这一新技术可能会带来一系列风险乃至社会问题。AI内容制作,让现实与虚拟的界线变得模糊。内容真实性、版权、隐私、数据、安全等问题纷至沓来。社会需要一套完善的政策、法律和伦理规范来应对,确保技术发展不脱轨,保护每个人的利益。 “人工智能将影响全球近四成工作岗位” 据《青年参考》消息,国际货币基金组织(IMF)表示,人工智能将影响全球近40%的工作岗位,应制定一套政策,利用人工智能的潜力造福人类。 IMF指出,与人工智能“高度互补”的工作岗位最安全,不易被取代,包括外科医生、律师和法官等。人工智能可以为从事这些职业的人提供帮助,而不是完全取代他们。电话推销员等与人工智能“低度互补”的工作岗位更易被取代。 IMF指出,政策制定者需要采取措施,为应对这一趋势做好准备,例如为易受人工智能影响的弱势劳动者提供培训等。 据悉,2023年11月,包括中国、美国、英国和欧盟在内的28个国家和地区,在首届人工智能安全峰会上签署《布莱奇利宣言》,同意协力打造一个“具有国际包容性”的前沿人工智能安全科学研究网络,以对尚未被完全了解的人工智能风险和能力加深理解。 中国青年报(ID: zqbcyol 整理:陈垠杉 )来 源:文 汇教育(姜澎)、每日经济新闻、中国新闻网( 吴涛 吴家驹)、《青年参考》等
-
Sora爆火!这些行业或面临迫切转型!是机会还是挑战?
清澈灵动的眼眸、活泼可爱的萌宠、神秘莫测的海底世界、熙熙攘攘的夏日街区、充满科技感的魔幻都市…… 这段场景逼真、色彩丰富、氛围浓厚的短视频,全部由人工智能系统制作生成。 近日,美国开放人工智能研究中心OpenAI发布首个视频生成模型“Sora”。该模型通过接收文本指令,即可生成60秒的短视频。而一年前,同样是这家研究中心发布的AI语言模型ChatGPT,让文本撰写和创作、检查代码程序等都变得易如反掌。 AI聊天、AI绘画、AI音乐……随着一系列AIGC(利用人工智能技术生成内容)相继问世,让众人直言对现代社会生活产生颠覆性影响的“AI革命”正式来临。 AI究竟有哪些“本领”?为何它每一次迭代升级都能引发全球热议? 生成式AI可将输入内容 变成小说、电影、艺术作品 谷歌公司旗下的人 工智能模型 “巴德”,可以根据你输入的多个词语迅速生成一篇短篇小说或诗歌。 今年2月,谷歌公司宣布“巴德”更名为“双子座”(Gemini)。这是一款多模态大模型,可理解和组合文本、代码、音频、图像和视频等不同类型的信息。 “巴德”用几个月的时间阅读互联网上几乎所有内容,并开发大语言模型,给出的答案就来自语言模型而并非网络搜索。 DALL-E可以把你输入的任何内容变成艺术作品。 为了训练DALL-E,研发公司为它提供了约6亿张来自互联网的标签图片。通过深度学习,它不仅可以理解单个物体,还可以学习不同物体之间的关系。 利用Runway,你在几秒钟内就能生成平时需要数日才能完成的视觉效果。 该公司创始人巴伦苏埃拉直言,有了生成式AI的加持,未来电影制作的门槛和成本将大大降低。 大模型理解、反映和模拟物理世界 成为可能 北京智源人工智能研究院副院长兼总工程师林咏华在接受央广网记者采访时指出,从技术路线来看,Diffusion架构是用于文生视频的标准算法框架,已在业内达成共识。相较于此前 Runway、Pika Labs等多家人工智能公司推出的文生视频大模型,Sora的“惊艳”之处体现在其对物理世界的理解和模拟能力。 “首先是对物理世界的模拟能力,Sora生成的视频无论是镜头的运动,包括很多三维视角的切换,都符合对物理世界的模拟,比如一些海浪翻滚、风吹草动的呈现等。”林咏华表示,Sora还体现了其对真实世界逻辑的推断和生成的能力,“比如一对情侣坐在沙滩上,沙滩边上突然出现一条鲨鱼,根据这么短短的一句话,Sora生成一个长达一分钟的视频,已经囊括了很多细节的变化,包括从鲨鱼出现之前,这对情侣在沙滩边岁月静好,表现出放松的表情和动作,逐渐过渡到鲨鱼从水里冒出来,靠近这对情侣时,两个人动作和神态的变化。” 在林咏华看来,从ChatGPT到Sora,既是人工智能技术的升级,但也不仅仅是简单的升级。“一直以来我认为GPT是一个困在数字世界的‘囚徒’,它不能够真实地感受、理解和反映物理世界。所以从ChatGPT到Sora,反映了大模型真实理解、反映和模拟物理世界的巨大能力,也让我们看到了这种巨大的可能性。” 将推动影视相关行业机构转型 Sora大模型的推出,除了让人们看到AI大模型的无限可能,也在一定范围上引发了“Sora是否会替代影视制作从业人员”的讨论和担忧。 林咏华指出,大模型会替人类完成一些任务,但不会完全取代人类的工作。“以Sora为代表的大模型的出现,更多是扮演辅助工具的角色,帮助人类提高效率,提高生产力。” 华泰证券研报指出,Sora等AI文生视频产品有望在电影、短视频、游戏等领域较大改变创作者的工作方式,降低创作成本,提升生产效率。 DCCI互联网研究院院长刘兴亮也对央广网记者表示,从Sora大模型对行业的影响来看,专业机构将面临迫切的转型。“要把它更好地作为一个工具利用起来。很多人因为Sora大模型的出现,对影视行业心存担忧,其实淘汰相关行业从业人员的,不是AI工具本身,而是那些掌握了类似Sora等AI工具的同行。所以相关行业的从业者必须要进行转型的思考。” 生物医疗、无人驾驶、气象预报…… AI技术市场规模巨大 除了在艺术创作领域,AI技术在医药领域、城市服务、气象预告的应用也十分值得关注。 1月29日,美国知名企业家马斯克表示,他旗下的脑机接口公司“神经连接”完成首例脑机接口设备人体移植,移植者状态良好。据悉,这项技术是完全可植入的,由电池供电且是无线,全程通过蓝牙连接。 清华大学官网1月30日发布消息,该校医学院脑机接口研究团队与首都医科大学宣武医院联合,于2023年10月成功进行全球首例无线微创脑机接口临床试验。 这位因车祸造成脊髓损伤、四肢瘫痪14年的患者,经术后三个月康复训练,已实现自主喝水等脑控功能,抓握准确率超过90%。 虽然脑机接口技术依旧面临许多挑战甚至质疑,但毋庸置疑的是,人工智能在医疗领域,特别是根据医学影像进行诊断方面取得显著成就。目前,美国食品和药物管理局已批准约420种涉及成像的算法,主要用于癌症治疗。这些算法的准确率可达80%至90%。 除了医学领域,生成式AI也将更广泛参与到城市公共服务、气象预报实践中。 库马尔是印度的一名卡车司机。他在高速公路跑车时,一个往返就是60小时,长时间疲劳驾驶很容易发生交通事故。如今,他的工作旅途中多了一个“不会说话”的小伙伴,随时提醒他避免疲劳或注意车距。 这是一台集合AI和计算机视觉驱动技术的终端设备。朝向外的摄像头可以测算车辆和其他物体间的距离关系。朝向司机的摄像头则会监控司机的行为和状态,如果司机打电话或者昏昏欲睡,设备就会提醒司机注意正确驾驶。 2023年7月,华为云盘古气象大模型正式上线欧洲中期天气预报官网,让世界看到中国大模型破解气象领域难题的能力。 世界银行估计,改进天气预报和早期预警系统每年不仅可带来价值1620亿美元的收益,还可以挽救约23000人的生命。 此外,目前AI人工智能在促进教育公平,应对老龄化社会方面也发挥着越来越重要的作用并形成巨大的市场规模。据彭博社预计,生成式AI的市场规模将在2032年扩大至1.3万亿美元。 AI生成欺骗性内容干扰选举 或在国家大选期间制造混乱 AI技术带来许多新机遇的同时,也不可避免造成前所未有的挑战和隐患。其中,人工智能生成欺骗性内容干扰选举被认为是全球面临的重要挑战。 当地时间1月23日,2024年美国总统选举共和党党内初选在新罕布什尔州举行。在此之前,很多美国选民都表示,自己接到一通“来自美国总统拜登的电话”。 这通电话以拜登的口头禅“真是一派胡言”开头,建议选民不要给特朗普投票,而是把选票留到11月大选时投给民主党。随后,白宫新闻秘书皮埃尔澄清说,这是一则伪造的电话录音。 分析人士担心,在美国选民容易受到错误信息影响的当下,人工智能可能会在大选期间制造出更多混乱。 据不完全统计,2024年全球将有70多个国家或地区举行重要选举,覆盖超过全球半数人口。在刚闭幕的第60届慕尼黑安全会议上,全球多家科技企业就签署协议,承诺将在2024年打击旨在干扰选举的人工智能滥用行为。 人工智能的应用方式 要充分遵守伦理规则 工业和信息化部赛迪研究院数据显示,2023年,我国生成式人工智能的企业采用率已达15%,市场规模约为14.4万亿元。制造业、零售业、电信行业和医疗健康等四大行业的生成式人工智能技术的采用率均取得较快增长。 专家预测,2035年生成式人工智能有望为全球贡献近90万亿元的经济价值,其中我国将突破30万亿元,占比超过四成。 • 如何看待未来人工智能的发展? 中国互联网协会副理事长、伏羲智库创始人李晓东分析,人工智能经历六七十年的发展,目前被广泛应用到科技创新、文化产业和工业制造等领域。算力提升和成本降低,也让通用人工智能来到普通百姓的身边。 可以预见在不久的将来,人工智能将无处不在,推动信息化技能从数字化、网络化,全面进入到智能化时代。“很快我们将不再讨论人工智能,因为人工智能已经融入到生活中,无处不在。”李晓东说。 从某种意义上讲,对人工智能的利用将会在国家之间、机构之间,甚至包括人与人之间形成新的代差和新的数字鸿沟,并推动人类从农业文明、工业文明走向数字文明。因此 能否充分学习和利用人工智能会对人类产生分化,甚至对人类文明产生巨大影响。 • AI快速发展,监管将面临哪些挑战? 李晓东表示,“数据获取+应用方式”是AI监管的两大问题。合理合法获取数据对人工智能至关重要,人工智能的应用方式也要充分遵守伦理规则。这两个核心问题如果处理不当,将会严重影响人工智能的发展和利用。 从数据获取方面看,采集和获取不仅涉及到数据的产权问题,还涉及到国家安全和个人隐私。如何合理合法获取数据,对于人工智能至关重要。 此外,如何有效联通数据故障,促进数据交换共享,提升数据之间的互操作能力也是人工智能的治理重点。否则,没有持续数据支撑的人工智能发展将会严重受损。 从人工智能的应用方式来看,人工智能以前所未有的方式展现其强大的信息处理能力,其本质是提升人类对信息的利用效率和效果。而人类社会有其基于特定国家和文化的法律法规和道德约束,人工智能发展也要充分遵从法律法规和道德伦理。 目前,部分人工智能技术确实对传统道德伦理及既定法律法规产生冲击,并产生全球性新的伦理规范和规则。而在规则规范形成过程中,要保持积极互动跟踪,推动伦理规范和全球规则朝着向上的轨道前行。 来源:央广网综合新闻联播 记者:黄昂瑾 本期编辑:毛嘉淇
-
AI逆天进化!?视频自己跟拍运镜,光影堪比王家卫!网友:以后还能信啥?
去年四月,纽约一家名为Runway AI的公司推出了一项技术,让人只需在屏幕上输入一个句子就可以生成视频。 当然彼时的效果仍不尽如人意,一眼就能看出是AI。 (AI生成画面) 没想到仅仅过去10个月,类似的技术就已经来到了全新的高度。 AI,又进化了。 今天OpenAI官宣了新产品Sora,号称可以生成“最长60秒的视频,其中包括高度丰富的场景、复杂的运镜、感情鲜活的多个人物”。 从目前OpenAI给出的演示视频看,这宣传词还真没多夸张…… 1.“大雪天,美丽、繁华的东京。镜头越过繁华的街景,跟随至几个人,他们享受着美丽的雪景,在附近的商摊购物。漂亮的樱花瓣和着雪随风飘落。” 视频1 细看仍然能看出一些问题:人体比例过于细长、两位主人物走的是个死胡同、有些樱花没有树枝飘在天上…… 但讲实话,这都是看第二遍之后才能发现的细节。第一眼看上去已经相当可信了。 估计再优化优化,就已经可以给那些不会画画的导演做分镜用了…… – 2.“几头巨型长毛猛犸踏着积雪的草地走向镜头,随着踏步,它们身上的长毛在微风中飘扬。远处是白雪覆盖的树木和壮观的雪山。” “午后的光线伴随着几缕云和远处高悬的太阳,发出温暖的光晕。较低的机位、优美的摄影和景深,捕捉到了这群巨大且毛茸茸的哺乳动物。” 视频2. 这个除了“AI味儿”比较明显之外甚至挑不出什么毛病。 – 3.“一位时尚女子走在东京街头,道上到处都是暖色的霓虹和动态的城市标志。她身穿黑色皮夹克、红色长裙、黑色靴子,手拿黑色皮毛,戴太阳镜,涂红色唇膏。” “她走得自信而随意。街道潮湿,反射出五颜六色的灯。镜头里还有许多行人走来走去。” 视频3 这可能是最震撼的一个,时长来到了一分钟,证明宣传语所言非虚。 配上一段小提琴,再加个红红黄黄的滤镜,旁白再来段什么“某年某月某日,东京。街头很冻,霓虹一直在闪,好似永远不会熄灭…….” 直接王家卫了。 这一分钟能找到的最大瑕疵在15~16秒处,人物左右脚突然交换了,但瑕不掩瑜。它很轻松就解决了“拍镜面怎么能不拍出摄影机”这一千古难题。 – 4.“一段电影预告片。讲述一位30岁太空人的冒险故事,他头戴红色羊毛织成的摩托车头盔。头顶蓝天,脚下盐碱沙漠,影院风格,以35mm胶片拍摄,色彩鲜艳。” 视频4 这一段是OpenAI故意整活,设计了一个针织帽头盔,搞得很出戏。但这段真的挺牛的,你甚至能看出一些镜头语言……. 一开始的越肩接怼脸特写用来介绍主角,飞船内外交替呈现,后面越切越快传达紧张感——它都会蒙太奇了…… 最离谱的是提示词只给了故事梗概、风格上的限定,上面这些拍摄手法全是它自己“悟”出来的,太科幻了……. – 5.“一个渲染得很华丽的珊瑚礁+纸艺的世界,到处都是五颜六色的鱼和海洋生物。” 视频5 – 6.“一段动画场景,一个矮小、毛茸茸的怪物跪在一根融化的红烛旁,近景。” “画面应该是3D写实风,重点在灯光和材质上。情绪基调是好奇、奇妙,小怪物要张大眼睛和嘴巴,凝视着蜡烛的火焰。” “它的姿势要传达出一种天真和俏皮的感觉,好像是第一次探索周围的世界。暖色调和夸张灯光的使用,进一步加强了画面的舒适温馨感。” 视频6 5和6一样,都是非写实风,感觉纯是OpenAI在秀肌肉,告诉人们“Sora不光能生成真实画面,还能做动画”。 也是,反正对于AI来说写实和动画没啥区别,反正都是从0开始生成的……. 以上就是OpenAI在推特上公布的6个演示视频,但他们官网上还有更多,篇幅所限就不再一一列举,感兴趣的话也可以自己去搜搜看。 其实除了开头提过的Runway AI之外,谷歌、Meta这两个大公司也尝试过“文本转视频”技术,但效果没有一个能接近Sora的。 其他公司的技术都只能生成大概十几秒,只有Sora能达到一分钟。 另外,Sora是一次性生成整个视频,而不是一帧一帧的生成。 这很大程度上保证了画面的连贯性,也就是说一个东西暂时出画面了,再回到画面来,还是同一个东西,而不是像下面这样连续变化,变着变着就诡异得没法看了: (诡异AI视频) 据OpenAI的工程师说,Sora这个名字来源于日语的“天空”,寓意差不多是“创造力突破天际”,现在看来,他们的期望多半要成真了。 目前Sora还是个测试版,可用性已经肉眼可见,天知道正式版会强成什么样……. 今天外网已经炸了,诸多媒体都已经报道了此事,“OpenAI”和“Sora”也已经登上了推特热搜: (“OpenAI”和“Sora”登上推特热搜) 但由于近一两年AI造成的各种骚乱:模仿声音诈骗、无成本造谣、版权问题、挤压工作岗位……大多数网友对Sora持比较悲观的态度。 不是嫌它不好用,是怕它太好用了。 “这太可怕了,还会偷走人们的工作,更不用说它可以用来干各种各样的坏事。” (出自推特网友评论) “喔天哪,以后到底啥才是真的……” (出自推特网友评论) “真是想不到它能用来干什么坏事呢呵呵” (出自推特网友评论) “你们这些科学家太忙于想着‘能不能’的事,却忘了停下来想想‘该不该’……” (出自推特网友评论) “下一个十年,将会是彻底疯狂的。” (出自推特网友评论) 甚至目前的Youtube一哥Mr.Beast也出来半开玩笑地表示: “Sam(指OpenAI的CEO Sam Altman)请别让我成流浪汉了…” (Mr.Beast评论) 另一位Youtube头部数码博主MKBHD也表示: “我…..我有好多好多疑问” (MKBHD评论) 再加上美国大选已经近在咫尺,很多人担心Sora会成为谣言的温床,干预到本次大选….. “安息吧。本次大选。” (出自推特网友评论) 网友的担忧不是没有道理的。毕竟很多中老年人是真的会相信“视频不能P”。 再说就凭演示视频这个质量……它真的只能骗到中老年人么? Sora还有一个功能是基于一张图生成整个视频,往好处想,这可以用来填充老视频缺失的帧; 但往坏处想,就真可以“开局一张图,剩下全靠编”了。 早在2023年5月时,推上就曾经有人发过一张“五角大楼炸了”的AI图,当时传播范围挺广,很多人信了,最后还被CNN报道了: (CNN报道的“五角大楼爆炸”) 现在的Sora生成的视频比这一张图更“可信”,潜在的引发骚乱的能力也更强了。 不过我们也不必太过担忧,OpenAI表示Sora也不是没有缺点,它最大的毛病有两个: 第一是理解不了因果关系,比如让它生成一个人咬饼干的视频,但咬完饼干可能没有咬痕; 第二则是缺乏空间意识,有时会混淆左右,不理解人和物体如何与场景交互。 等正式版发布,也许这些问题能得到解决,但相应地,引发骚乱的可能也会变大。 OpenAI也清楚这一点,所以他们目前还没有把Sora放出来,而是找了一群学者专家合作,想法设法地找寻Sora可能被滥用的点。 然而从过去几年发生的事看,他们恐怕很难把所有口子都彻底堵上,总会有人尝试给AI越狱,不是想防就能防得住……. 所以下面这位网友预想的场景,也许真有实现的一天: “我被抓了,法庭上展出了‘视频证据’,里面是我在犯罪,一件我这辈子都没犯过的罪。” (出自推特网友评论) 就在两天前,OpenAI对我们最熟悉的ChatGPT做出了改动,现在它的“记性”更好了。 (相关报道) 比如在《纽约时报》的这篇报道中,记者跟GPT聊天说他有个女儿叫Lina,马上五岁了,她喜欢粉色、喜欢水母。 等下次再跟GPT聊天,记者让GPT为女儿生成一张生日贺卡,它就直接调用了以前的信息: (AI生成的贺卡) 这说明它记住了以前的聊天,变得更像个“人”了…… 似乎来到2024之后,OpenAI加快了推进AI的脚步,Sora的出现就是一个明证。 一方面,Sora的前景让人十分期待,用来“拍电影”不行,但一分钟之内的短视频它足以胜任; 另一方面,超低成本的造谣也是明摆着很难解决的问题。 OpenAI究竟是在创造科技进步还是在打开潘多拉魔盒,也许最终就只能交给时间来评判了…… ref: https://www.nytimes.com/2024/02/15/technology/openai-sora-videos.html https://twitter.com/OpenAI/status/1758192957386342435
-
深度解读Sora官方技术报告:OpenAI的下一个王炸?
郭晓静、郝博阳 作者 金鹿 编译 OpenAI 2月16日凌晨发布了文生视频大模型Sora,在科技圈引起一连串的震惊和感叹,在2023年,我们见证了文生文、文生图的进展速度,视频可以说是人类被AI攻占最慢的一块“处女地”。而在2024年开年,OpenAI就发布了王炸文生视频大模型Sora,它能够仅仅根据提示词,生成60s的连贯视频,“碾压”了行业目前大概只有平均“4s”的视频生成长度。 为了方便理解,我们简单总结了这个模型的强大之处: 1. 文本到视频生成能力:Sora能够根据用户提供的文本描述生成长达60s的视频,这些视频不仅保持了视觉品质,而且完整准确还原了用户的提示语。 2. 复杂场景和角色生成能力:Sora能够生成包含多个角色、特定运动类型以及主题精确、背景细节复杂的场景。它能够创造出生动的角色表情和复杂的运镜,使得生成的视频具有高度的逼真性和叙事效果。3. 语言理解能力:Sora拥有深入的语言理解能力,能够准确解释提示并生成能表达丰富情感的角色。这使得模型能够更好地理解用户的文本指令,并在生成的视频内容中忠实地反映这些指令。4. 多镜头生成能力:Sora可以在单个生成的视频中创建多个镜头,同时保持角色和视觉风格的一致性。这种能力对于制作电影预告片、动画或其他需要多视角展示的内容非常有用。5. 从静态图像生成视频能力:Sora不仅能够从文本生成视频,还能够从现有的 静态图像开始,准确地动画化图像内容,或者扩展现有视频,填补视频中的缺失帧。6. 物理世界模拟能力:Sora展示了人工智能在理解真实世界场景并与之互动的能力,这是朝着实现通用人工智能 (AGI) 的重要一步。它能够模拟真实物理世界的运动,如物体的移动和相互作用。 可以说,Sora的出现,预示着一个全新的视觉叙事时代的到来,它能够将人们的想象力转化为生动的动态画面,将文字的魔力转化为视觉的盛宴。在这个由数据和算法编织的未来,Sora正以其独特的方式,重新定义着我们与数字世界的互动。一反常态,OpenAI在模型公布后的不久,就公布了相关的技术Paper,我们第一时间“啃”了这篇技术报告,希望能够帮助大家理解到底有哪些神奇的技术,让Sora能够有如此强大的魔力。 OpenAI文生视频模型 Sora 官方技术报告 我们探索了利用视频数据对生成模型进行大规模训练。具体来说,我们在不同持续时间、分辨率和纵横比的视频和图像上联合训练了以文本为输入条件的扩散模型。我们引入了一种transformer架构,该架构对视频的时空序列包和图像潜在编码进行操作。我们最顶尖的模型Sora已经能够生成最长一分钟的高保真视频,这标志着我们在视频生成领域取得了重大突破。我们的研究结果表明,通过扩大视频生成模型的规模,我们有望构建出能够模拟物理世界的通用模拟器,这无疑是一条极具前景的发展道路。 Sora生成的东京街头场景视频 这份技术报告主要聚焦于两大方面:首先,我们详细介绍了一种将各类可视数据转化为统一表示的方法,从而实现了对生成式模型的大规模训练;其次,我们对Sora的能力及其局限性进行了深入的定性评估。需要注意的是,本报告并未涉及模型的具体技术细节。 在过去的研究中,许多团队已经尝试使用递归网络、生成对抗网络、自回归Transformer和扩散模型等各种方法,对视频数据的生成式建模进行了深入研究。然而,这些工作通常仅限于较窄类别的视觉数据、较短的视频或固定大小的视频上。相比之下,Sora作为一款通用的视觉数据模型,其卓越之处在于能够生成跨越不同持续时间、纵横比和分辨率的视频和图像,甚至包括生成长达一分钟的高清视频。 将可视数据转换成数据包 (patchs) 在可视数据的处理上,我们借鉴了大语言模型的成功经验。这些模型通过对互联网规模的数据进行训练,获得了强大的通用能力。同样,我们考虑如何将这种优势引入到可视数据的生成式模型中。大语言模型通过token将各种形式的文本代码、数学和自然语言统一起来,而Sora则通过视觉包 (patchs) 实现了类似的效果。我们发现,对于不同类型的视频和图像,包是一种高度可扩展且有效的表示方式,对于训练生成模型具有重要意义。 OpenAI专门设计的解 码器模型,它可以将生成的潜在表示重新映射回像素空间 在更高层次上,我们首先将视频压缩到一个低维度的潜在空间:这是通过对视频进行时间和空间上的压缩实现的。这个潜在空间可以看作是一个“时空包”的集合,从而将原始视频转化为这些包。 视频压缩网络 我们专门训练了一个网络,专门负责降低视觉数据的维度。这个网络接收原始视频作为输入,并输出经过压缩的潜在表示。Sora模型就是在这个压缩后的潜在空间中接受训练,并最终生成视频。此外,我们还设计了一个解码器模型,它可以将生成的潜在表示重新映射回像素空间,从而生成可视的视频或图像。 时空包 当给定一个压缩后的输入视频时,我们会从中提取出一系列的时空包,这些包被用作转换token。这一方案不仅适用于视频,因为视频本质上就是由连续帧构成的,所以图像也可以看作是单帧的视频。通过这种基于包的表示方式,Sora能够跨越不同分辨率、持续时间和纵横比的视频和图像进行训练。在推理阶段,我们只需在适当大小的网格中安排随机初始化的包,就可以控制生成视频的大小和分辨率。 用于视频生成的缩放Transformers Sora是一个扩散模型,它接受输入的噪声包 (以及如文本提示等条件性输入信息) ,然后被训练去预测原始的“干净”包。重要的是,Sora是一个基于扩散的转换器模型,这种模型已经在多个领域展现了显著的扩展性,包括语言建模、计算机视觉以及图像生成等领域。 随着训练量的增加 扩散转换器生成的样本质量有了明显提高 在这项工作中,我们发现扩散转换器在视频生成领域同样具有巨大的潜力。我们展示了不同训练阶段下,使用相同种子和输入的视频样本对比,结果证明了随着训练量的增加,样本质量有着明显的提高。 丰富的持续时间、分辨率与纵横比 过去,图像和视频生成方法常常需要将视频调整大小、裁剪或修剪至标准尺寸,如4秒、256×256分辨率的视频。但Sora打破了这一常规,它直接在原始大小的数据上进行训练,从而带来了诸多优势。 采样更灵活 Sora具备出色的采样能力,无论是宽屏1920x1080p视频、垂直1080×1920视频,还是介于两者之间的任何视频尺寸,它都能轻松应对。这意味着Sora可以为各种设备生成与其原始纵横比完美匹配的内容。更令人惊叹的是,即使在生成全分辨率内容之前,Sora也能以较小的尺寸迅速创建内容原型。而所有这一切,都得益于使用相同的模型。 Sora可以为各种设备生成与其原始纵横比完美匹配的内容 改进构图与框架 我们的实验结果显示,在视频的原始纵横比上进行训练,能够显著提升构图和框架的质量。为了验证这一点,我们将Sora与一个将所有训练视频裁剪为方形的模型版本进行了比较。结果发现,在正方形裁剪上训练的模型有时会生成仅部分显示主题的视频。而Sora则能呈现出更加完美的帧,充分展现了其在视频生成领域的卓越性能。 将所有训练视频裁剪为方形的模型相比(左),Sora能呈现出更加完美的帧 语言理解深化 为了训练文本转视频生成系统,需要大量带有相应文本字幕的视频。为此,我们借鉴了DALL·E3中的re-captioning技术,并应用于视频领域。首先,我们训练了一个高度描述性的转译员模型,然后使用它为我们训练集中的所有视频生成文本转译。通过这种方式,我们发现对高度描述性的视频转译进行训练,可以显著提高文本保真度和视频的整体质量。 与此同时,与DALL·E3类似,我们还利用GPT技术将简短的用户提示转换为更长的详细转译,并将其发送到视频模型。这一创新使得Sora能够精确地按照用户提示生成高质量的视频。 图片与视频提示 在上述所有结果和我们的演示中,你可能已经注意到了文本转视频的示例。但Sora的功能远不止于此,它还能接受其他类型的输入提示,如预先存在的图像或视频。这种多样化的提示方式使Sora能够执行广泛的图像和视频编辑任务,如创建完美的循环视频、将静态图像转化为动画、向前或向后扩展视频等。 将DALL·E图片变成动画 值得一提的是,Sora还能在提供图像和提示作为输入的情况下生成视频。下面展示的示例视频就是基于DALL·E 2和DALL·E 3的图像生成的。这些示例不仅证明了Sora的强大功能,还展示了它在图像和视频编辑领域的无限潜力。 一只戴着贝雷帽、穿着黑色高领毛衣的柴犬生成视频 一幅逼真的云朵图像生成视频,上面写着“SORA” 在一个华丽的历史大厅里,一股巨大的浪潮达到顶峰,并开始崩散,两个冲浪者抓住时机,巧妙地在海浪表面飞驰 扩展生成视频 Sora不仅具备生成视频的能力,更能在时间维度上实现向前或向后的无限扩展。以下三个视频便是从同一生成视频片段出发,逐步向后扩展的示例。尽管它们的起始部分各异,但结局却出奇地一致。 这些视频的起始部分各异,但结局几乎相同 这充分展示了Sora在时间扩展方面的强大功能,甚至能创造出无缝的无限循环视频。 Sora甚至可以创造出无限循环视频 视频到视频编辑 随着扩散模型的发展,我们已经开发出多种方法来编辑基于文本提示的图像和视频。在此,我们将其中一种名为SDEdit 32的技术应用于Sora。这项技术赋予了Sora转换零拍摄输入视频风格和环境的能力,为视频编辑领域带来了革命性的变革。 视频的无缝连接 更令人惊叹的是,Sora还能在两个截然不同的输入视频之间实现无缝过渡。通过逐渐插入技术,我们能够在具有完全不同主题和场景构图的视频之间创建出流畅自然的过渡效果。 图片生成能力 Sora的出色能力不止于数据处理和分析,它现在还能生成图像!这一创新功能的实现得益于一种独特的算法,该算法在一个精确的时间范围内,巧妙地在空间网格中排列高斯噪声补丁。 值得一提的是,Sora的图像生成功能不仅限于特定大小的图像。它可以根据用户需求,生成可变大小的图像,最高可达惊人的2048 × 2048分辨率。 一个女人在秋天的特写肖像,每一个细节都被捕捉得淋漓尽致,浅景深的应用使得主体脱颖而出 充满生机的珊瑚礁吸引了五颜六色的鱼类和海洋生物 新的模拟能力 在大规模训练过程中,我们发现视频模型展现出了许多令人兴奋的新能力。这些功能使得Sora能够模拟现实世界中的人物、动物和环境等某些方面。值得注意的是,这些属性的出现并没有依赖于任何明确的3D建模、物体识别等归纳偏差,而是纯粹通过模型的尺度扩展而自然涌现的。 3D一致性: 在3D一致性方面,Sora能够生成带有动态摄像头运动的视频。 随着摄像头的移动和旋转,人物和场景元素在三维空间中始终保持一致的运动规律。 人物和场景元素在三维空间中始终保持一致 较长视频的连贯性和对象持久性: 视频生成领域面对的一个重要挑战就是,在生成的较长视频中保持时空连贯性和一致性 。 Sora,虽然不总是,但经常能够有效地为短期和长期物体间的依赖关系建模。 例如,在生成的视频中,人物、动物和物体即使在被遮挡或离开画面后,仍能被准确地保存和呈现。 同样地,Sora能够在单个样本中生成同一角色的多个镜头,并在整个视频中保持其外观的一致性。 与世界互动: Sora有时还能以简单的方式模拟影响世界状态的行为。 例如,画家可以在画布上留下新的笔触。 随着时间的推移,一个人吃汉堡时也能在上面留下咬痕。 Sora能以简单的方式模拟影响世界状态的行为 模拟数字世界: Sora还能够模拟人工过程,比如视频游戏。 它可以在高保真度渲染世界及其动态的同时,用基本策略控制《我的世界》中的玩家。 这些功能都无需额外的训练数据或调整模型参数,只需向Sora提示“我的世界”即可实现。 这些新能力表明,视频模型的持续扩展为开发高性能的物理和数字世界模拟器提供了一条充满希望的道路。通过模拟生活在这些世界中的物体、动物和人等实体,我们可以更深入地理解现实世界的运行规律,并开发出更加逼真、自然的视频生成技术。 局限性与展望 尽管Sora在模拟能力方面已经取得了显著的进展,但它目前仍然存在许多局限性。例如,它不能准确地模拟许多基本相互作用的物理过程,如玻璃破碎等。此外,在某些交互场景中,比如吃东西时,Sora并不能总是产生正确的对象状态变化。我们在发布页面中列举了模型的其他常见故障模式,包括在长时间样本中发展的不一致性或某些对象不受控的出现等。 然而,我们相信随着技术的不断进步和创新,Sora所展现出的能力预示着视频模型持续扩展的巨大潜力。未来,我们期待看到更加先进的视频生成技术,能够更准确地模拟现实世界中的各种现象和行为,并为我们带来更加逼真、自然的视觉体验。 圈内人如何看Sora? 最后再来看看各位技术大牛和内容行业从业者如何评价Sora?…
-
Sora互联网纪实:卖课割韭菜、A股大涨停
本文来自微信公众号: 娱乐资本论(ID:yulezibenlun) ,作者:小如,原文标题:《Sora互联网纪实:卖课割韭菜、私域带你飞、A股大涨停、影视圈淡定》,头图来自:电影《华尔街之狼》剧照 2月15日,Open AI发布了首个文生视频模型Sora,可以生成长达60s、多机位、具备高度拟真细节的镜头。引发了无数人的关注和讨论。 Sora在AI生成视频方面彰显出的能力,可以说改变了全球AI视频赛道的格局,有望颠覆现有的内容行业。联系到大语言模型ChatGPT和文生图工具Midjourney,Sora有着太多的想象空间。 一石激起千层浪,科技大佬、AI创业者、技术人员乃至微课微商等群体纷纷下场评论,A股证券公司、有关无关的上市公司纷纷下场讨论Sora为行业带来的改变。 河豚君在朋友圈里频频刷到各类Sora卖课消息,价格从9.9到1999不等,有人称自己一天内遇到了5波Sora卖课的推荐者。有非电影圈人士两天组建了9个Sora群,发布了剧本征集令,称要打造“世界首部AI电影”。低迷了甚久,被股民们踩在脚下的股市因为Sora吸了一口阳气,A股多家AI类公司股价上涨,证券纷纷发声叫好。 看上去,这一次唯独影视圈独善其身。 一、卖课圈:还未公测就已开放教学 2月18日,某自称为“执剑人”博主推出了原价365,现价99的《Sora一键文生视频》的课程,称要教会学员如何使用Sora专属提示词库,Sora提示词技巧,该课程可以拓展教育边界、降本增效、创新教育方式。 河豚君也看到,有卖课的人在朋友圈说,Sora太火,直接转钱要学习的人很多。这几天我就安排同事熟悉了Sora再培训大家。 甚至有人号称自己有北美NASA工作人员的资源,已经拿到了接口,把Sora打包到了GPTs,做成了软件发布上线。 资料、付费课、社群、专栏,挥着Sora旗号收割的方式各种各样。知识星球上,搜“AI破局”不乏上万人的收费群。一个群的宣传中只要有“破局”“战队”这种词,基本都在割韭菜。 实际上,Sora正处于内测阶段,并未对外开放。即使开放,该工具能够作为产品使用的时间仍旧遥遥无期。也就是说,这位博主在完全没用过Sora的情况下称要卖课。 这不是割韭菜,是诈骗。 值得一提的是,2月18日,“执剑人”博主道歉,称“因为盲目追求速度而忽略内容的准确性,占用了舆论空间,对不起。”全篇未提停课退款,怎么交付课程。道歉书更像是没有割到韭菜反惹一身骚的“止损书”。 割韭菜的消息甚至传到了OpenAI的开发者推广负责人Logan眼里,他赶紧发了推特澄清:我们尚未推出对Sora的访问。 二、私域圈:交上999带你飞 卖课之外,现在不少人在用Sora的热度积攒私域流量。 一种是搜集各类Sora的公众号文章、视频行业专有名字等资料,发在微信公众号、小红书、微博等渠道上引流。或者做成飞书文档直接卖钱。 一种是发布Sora的视频,或者直接找别的视频伪装成Sora的视频发布引流。 一种是直接套用影视行业的专业名词,将其包装成Sora的提示词。 还有人直接发个二维码在朋友圈拉群,称,“Sora首部AI电影共创剧本海选开始!您有好作品,可以来加入我们共创,一起开启新时代!”“我们都可以成为第一代AI导演!” 这些说要做导演的人,也许根本没拍过短片。先把概念打出去,吸引用户,能不能落地都是后话。 更努力的博主,则会像地推人员一样一个个在AI群里加好友,他们加了娱乐资本论·视智未来后立马发私信,“你要不要改变命运?要不要破圈?缴上999,一起走向新世界的大门。” 更谨慎的,则会借着Sora的理由,卖《短视频矩阵引流解决方案》的相关课程,称先学好这个,才能成为第一波靠Sora赚钱的人。 实际上,用户想入门学习的话门道很多。B站上、微信公众号上,懂AI技术,能产出AIGC好内容的博主很多,免费教程一堆。Sora带来的“AI韭菜事件”,本质上和小区门口发鸡蛋吸引大妈大伯听培训买保健品一样,都是通过贩卖焦虑,赚信息差的钱,本质上就是割韭菜。 当自媒体用夸张的手法,再来叙述普通网友接触不到的ChatGPT、Sora这些技术时,更大的信息差,更猛烈的镰刀也随之而来。 而被吸引的人,很多还是因为自己有惰性、认知不够。不主动寻找靠谱的信息源,决策能力差,想发财又懒得花功夫研究。 AI是工具,不要先没有学会用工具,反而被别人割了一波。 三、A股圈:券商发研报概念股涨停20% AI狂奔的2023年,曾多次引发A股暴涨。龙年的首个交易日里,A股因为AI多只个股涨停,甚至引发周鸿祎等名人纷纷高位离婚。 近日,有超过14家券商,发布了19份Sora研报,表达对AI视频的看法。 银河、平安、中信建投、国泰君安、申万宏源、招商、天风、华泰、中信、长江等10家券商认为,Sora 是人工智能发展进程中的“里程碑”,会给行业带来颠覆性的变革。算力、算法、应用场景、网络安全等都是值得关注的方向。 2月19日的A股中,会畅通信、当虹科技、万兴科技等多个AI概念股有“20cm”涨停。视觉领域相关的海康威视、大华股份也出现大涨,并行科技涨超25%,新元科技涨超16%,高新发展封板涨停。 板块涨幅方面,AIGC概念板块涨幅超6%,多模态AI板块涨幅超7%,算力相关和短剧游戏板块的涨幅均超4%。此外,虚拟数字人板块也有增长。 四、海外科技圈:Adobe等暴跌 随着OpenAI与风险投资公司Thrive capital达成最新股票出售协议,OpenAI的估值已经超过了800亿美元。其估值已经涨到了九个月前的近3倍,成为全球估值第三高的初创企业。但OpenAI首席执行官奥特曼表示公司无意上市。 GitHub Copilot主创Alex Graveley则说道:“如果OpenAI打算继续逐个行业地蚕食AI初创公司,他们应该尽快上市。构建一个只有500人受益的新经济是个糟糕的未来。” 有人欢喜有人愁。 当OpenAI甩开其他公司狂奔时,其他的内容类公司的日子各有忧愁。 Sora公布后的次日,工具类公司Adobe在二级市场上的股价暴跌超7%。 生产照片和视频的公司,Shutterstock在美股上跌逾5%,市值一夜蒸发7000多万美元。 值得一提的是,Sora公布后,2月16日发布的谷歌最新多模态模型Gemini Pro 1.5几乎无人关注。Sora将视频生成的时长提高了15倍,远远甩开了现在市面上的AI视频生成工具,这将会改变全球的 AI 视频生成的企业现状,有些企业将会直接出局。 出门问问创始人李志飞感慨:“LLM ChatGPT是虚拟思维世界的模拟器,以LLM为基础的视频生成模型Sora是物理世界的模拟器,物理和虚拟世界都被建模和模拟了,到底什么是现实?” 美国旧金山早期投资人Zak Kukoff预测:一个不到5人的团队将在5年内用文生视频模型和非工会的劳动力。制作一部票房收入超过5000万美元的电影。 至于按道理更会被影响的中国影视行业,这一次则显得尤为低调,在2月19日A股开盘后,其中影视相关的股票,基本上属于微涨微跌,但背后涨跌几乎和这一波的Sora没有半毛钱关系。 在视智未来看来,最怕的事情是,未来会如一位AI视频创业者对Sora产品的感慨:“我有些害怕科技巨头的产品像隆隆火车一样驶过,而我做的东西如同路边的野草一样,在这个技术进步就像跑马灯一样的时代里,留不下一丝痕迹。” 本文来自微信公众号: 娱乐资本论(ID:yulezibenlun) ,作者:小如 *免责声明:本文章为作者独立观点,不代表微克立场。
-
Sora炸裂科技圈:真神还是焦虑制造机
作者:吴狄 编辑:胡展嘉 运营:陈佳慧 来源:零态LT(ID:LingTai_LT) 周鸿祎又口出狂言了。 他说,“AGI(通用人工智能)的实现将从10年缩短到1年”,而背后的原因,仅仅是因为一个1分钟的短视频。 注意看,这个女人叫小美,她正向我们走来。虽然身处日本某条热闹的大街,小美却总是不停地回头张望,似乎在暗示观众镜头之外隐藏了不为人知的秘密。 ▲图:主角出场 镜头拉近,可以清晰看到小美修长的脖子和优美的下颌线,让整个画面充满了令人无法抗拒的神秘和美感。 ▲图:细节展示 实际上,整个短视频中,从街景到行人,包括小美,在现实中根本不存在。这是OpenAI最新产品Sora制作的演示视频,而正是这个视频,让周鸿祎做出了AGI发展将会10倍提速的预言。 传统方式制作这样一段1分钟的视频成本非常高。除了需要选址,选演员,提前进行分镜构图,架设机位外等,想要碰上如此理想的天气,还需要赌一赌运气。落日转瞬即逝,一旦失误就只能第二天重头来过。 拍摄完成后,是非常耗时的后期制作。不仅要调整画面色调,还要仔细核对画面中是否有瑕疵,比如眼镜反射的画面会不会导致穿帮、路人中是否出现不协调元素等等。 但Sora出马,全部流程就是(字面意义上的)一句话的事。 Sora官网上公布了十几段“制作”精良的高清演示短片, 从现实人物到3D动画,所有短片都是通过一句话生成的。 ▲图:Sora展示视频 看过这些短片后,我科技圈的朋友集体表示“炸裂”;大众圈的朋友表示“AI都到了这种程度了吗”;而摄影圈的朋友表示,尽管还是能看出和人类摄影师有一点点差距,但依然被Sora的效果震撼了,进而纷纷开始和我讨论起失业以后,除了送外卖还可以从事什么工作。 但如果我们抛开网上铺天盖地、对Sora近乎玄幻的赞誉,跳出官网演示视频的魅惑就会发现,Sora本质上是生成式AI在视频领域的一个应用,一个diffusion transformer模型。 而官方宣传的Sora所有功能,例如通过文字或者图片生成高清短视频,在此基础上进行扩展生成一段更长的视频等,其实很多公司都在做。比较知名的产品包括已经商用的Runway,免费的Pika,以及还在完善阶段的Google Lumiere、Meta Make-A-Video,还有一些知名度稍低的产品如Leonardo,FinalFrame等等。 这里就有一个很大的疑问:凭什么出圈的又是Sora,它真有网上说的那么神吗? 凭借更逼真的效果 OpenAI再次出圈 1月24日,谷歌研究人员公布了一段Lumiere的演示视频。画质非常高清,且真实。 ▲图:由Lumiere生成的游泳海龟视频 Lumiere除了可以生成真实图片外,还可以实现一键换装、根据图片和提示词生成动态视频等功能。 ▲图:一键换装 ▲图:通过图片生成视频 2月15日,刚刚过完情人节的谷歌在疯狂星期四又重磅推出了下一代AI产品Gemini 1.5。在此前的演示视频中,Gemini已经展现了其在图像识别和多轮对话中的逆天能力。 演示视频中,演示人员画了一个类似鸭子的轮廓让Gemini辨认,Gemini表示它觉得像个鸟。 ▲图:Gemini演示 但是当演示人员画上了波浪后,Gemini表示通过长脖子长嘴又会游泳这几个依据,判断这是只鸭子。 ▲图:Gemini演示 随后演示人员拿了个玩具小鸭子问Gemini这个东西是什么材质做的,Gemini表示看起来可能是橡胶也可能是塑料。而当演示人员捏响橡胶鸭子后,Gemini立刻判断出是用柔软的橡胶做成的。 ▲图:Gemini演示 就在圈内很多人认为谷歌将要凭借Lumiere和Gemini拿下今年头条的时候,OpenAI仅仅用Sora就轻松获得了更高的关注度。 Sora这个词很有意思,它在韩语中表示海螺壳,在日语中表示天空,在芬兰语中表示砂砾。这就很难不让人想到《海底两万里》的鹦鹉螺号,《沙丘》,以及“我们的目标是星辰大海”的豪情壮志。 而且Sora是一个比较常见的名字,比Lumiere(法语,光)更短、更好读。 和GPT当年的故事如出一辙,Sora也是踩着竞争对手以碾压式的优势胜出。相比同类产品,Sora能抓住提示词的精髓,巧妙地生成具有多个角色和特定动作的场景。 有人做过对比,使用同样的提示词,让AI生成一个在花园里、似乎正在追逐什么东西、快乐奔跑的黄白相间的猫,最终结果的差距十分明显。 ▲图:不同AI产品的效果对比 上面由Sora生成的视频看起来非常真实,甚至在奔跑时候,猫腮帮子上的毛都会随着脑袋起伏。而下面通过Pika, Runway, Leonardo, FinalFrame生成的视频,猫不仅看起来不像真的,连动作都很诡异。 在生成的视频时长上,Sora也碾压友商。Sora可以生成1分钟的视频,相对的,Pika是3秒,Runway是4秒,Lumiere是5秒。 最重要的是,Sora有望解决一个生成式AI的痛点,那就是同样的提示词通常不会生成同样的结果,例如“黄白相间的猫”这个提示词,不同的视频里会出现不同模样的黄白相间的猫。导致的结果,就是无法通过拼接来创作更长的视频。 尽管Sora一出道就秀出了远超同行的肌肉,但Sora并没有选择像Pika、Runway一样,开放给大众使用,而是采取了Google、Meta类似的保守策略,先官宣来吊足大家胃口,然后慢慢内测,等待一个合适的时机,再向大众开放。 因为,有很多关键问题,大家都没有找到好的解决方案。 AI一调皮 人类就头疼 生成式AI天生就有一个“不按物理定律出牌”的老毛病,即便是看起来已经非常接近真实世界的Sora也不例外。这个问题过于明显,以至于OpenAI都懒得去遮掩,干脆自己先大方的说了出来。 从内测用户流出的视频可以发现,Sora无视物理法则随意发挥的意愿十分高涨,而这种意愿在“必须还原物理世界”的规则约束下,很容易生成像人类做梦一样的场景。有过做梦经历的朋友应该会这样的体会:明明梦是虚幻的,但在梦里你的感受又很“真实”。 下面就是个很典型的例子。 ▲图:Sora的梦境物理 注意看,视频中的这个杯子莫名其妙的跳了起来并侧翻在桌面上,杯中的液体在杯子跳起来的一瞬间穿透了杯底铺满桌面,而最终杯子连同里面剩余的液体一起,融进了桌面。 ▲图:融进桌面的杯子 这样的视频显然无法应用在正式的场合,大概率只能出现在B站的鬼畜区,告诉你一个学了3年动画的人,是如何因为一个毕业作品被老师轰出门外的故事。 此外,Sora对算力有很高的要求。下面这个视频演示了低算力和高算力之间的差距能有多可怕。 ▲图:算力差距 而想要高算力,就得花更多的钱。 以Runway为例,个人版收费模式分3档,标准版为每月15美元,可以制作一个125秒的Gen-1视频,或者44秒的Gen-2视频,相当于每秒1-2.4元人民币,超出部分需要额外付费。Pro版每月35美元,至尊版每月95美元。而用户如果希望加快视频的产出效率,也需要额外购买“时间”。 能力越大 危险越大 生成式AI在社会层面有几个老生常谈的问题。 首先就是造假问题。AI生成的视频越真实,造假就越容易。最直接的解决办法是将AI生成的内容打上一个特殊的标签,以便于平台将其和人工拍摄的视频进行区分,OpenAI和Google的确也在做这件事。 但水印的问题在于,它可以在分享的过程中会被人恶意抹除。例如通过截图、录屏的方式获得视频副本,不会带有任何水印。 其次是版权问题。版权问题比造假更加复杂,它既是一个形而上的宏大概念,又和每一个创作者的个人利益息息相关。目前对版权的争论主要集中在AI和人类对齐的过程中,比如,AI通过学习别的艺术家的风格在此基础上进行的创作,和人类以同样方式进行的创作,本质上有没有区别? 而更直白的问题则是,AI到底是来帮我赚钱的,还是来跟我抢钱呢? 这些问题一个比一个难解决,也就意味着Sora们至少在短时间内不会向公众开放。从某种角度来看,这或许对于视频制作者是一个好消息,至少有了更多的缓冲时间,来思考如何应对接下来Sora们带来的冲击。 无论如何,Sora们向公众开放,只是时间问题,至于会不会像周鸿祎预言的那么快,可能还存在疑问。但有一点毫无疑问: 那时候的Sora们,将比现在更加强大。 -对于近日爆火的Sora,你有何看法? 欢迎在评论区留言,我们将从留言中选择七天点赞数最高的一位同学送出鸟哥笔记精美周边~
-
Sora的第一波受害者出现了
产业巨大变革。 作者:南意 来源:ETF进化论 有时候生活中的无力感就是,你明知道世界正在发生巨大颠覆,却无法参与这一变迁,只能旁观他人的狂欢,甚至你还清楚不久的将来,你的生活一定会因此被裹挟着向前。 Open AI正是这么一家改变全人类生活的伟大公司,继文本模型ChatGPT、图像模型Dall-E大杀四方后,OpenAI继续祭出大杀器——Sora,这回他们选择颠覆视频领域。01Sora是什么?2月15日,Open AI发布了第一款文生视频模型Sora,能够生成一分钟的高保真视频,一石激起千层浪。 Open AI自称Sora是“世界模拟器”。人们惊呼:“真实世界不再存在。”马斯克直言:人类认赌服输。前阿里VP贾扬清评价Sora:真的非常牛。英伟达高级研究科学家兼人工智能代理负责人Jim Fan认为Sora代表了文本生成视频的 GPT-3 时刻。 Sora到底是什么?相比同类产品如Runway和Pika强在哪? 目前市面上文生视频模型的主流技术路线主要有两种:一种基于Transformer模型的技术路线,即从文本及图像中生成,另一种则是基于扩散模型(Diffusion model),如 Runway。 Sora牛就牛在是融合了两者的Diffusion Transformer模型,通过扩散模型(DALL-E3)和转换器架构(ChatGPT)组合,Sora不用预测序列中的下一个文本,而是预测序列中的下一个“Patch”。 这意味着Sora是基于“Patch”,而非整个视频进行训练的,有点类似ChatGPT用Token处理文本一样处理视频,因此,Sora可以高效处理更多的数据,输出质量也会更高。 事实上,Sora公布的演示视频最令人印象深刻的特点是逼真地模拟物理世界,视频效果吊打市面上同类产品如Runway和Pika。 今日Sora的背后团队再次最新公布新的生成视频作品,这回连同一场景下的多角度机位都出现了。 02Sora的受害者是谁?从ChatGPT开启生成式AI时代距今,也不过仅仅一年的时间,我们还在学习怎么用指示性句子更好使用ChatGPT,当大家在怀疑AI变懒了,Sora的现身可谓是石破天惊,现在所有人开始怀疑真实世界和虚拟世界的界限。 AI的进化速度远超预期,毋庸置疑,AIGC极具破坏性创新的潜力,现有的产业格局如短视频、广告、游戏、影视行业等产业格局一定会被重塑,首当其冲的是谁? 从二级市场的表现来看,是工具类公司Adobe,在Sora公布后的次日股价暴跌超7%。 另外一只美股Shutterstock周五跌逾5%,市值一夜蒸发超7000万美元。公开资料显示,该公司每年销售价值约10 亿美元的照片和视频。 也是,Sora的出现直接让网友都惊呼:“以后网络小说家可以直接生产电影给我们看了?”另一网友直接一针见血道:“你觉得再发展下去,还有网络小说家吗?ChatGPT不干了?” 也是,AI都猛这样了,想要什么,直接给你一键生成,卖图片的公司还有什么存在的价值吗? Sora的影响到底有多大? 03Sora影响有多大?360董事长周鸿祎点评道:今天Sora可能给广告业、电影预告片、短视频行业带来巨大的颠覆,但它不一定那么快击败TikTok,更可能成为TikTok的创作工具。此外,他认为,中美两国的人工智能差距在拉大。 前阿里VP、正在AI infra赛道创业的贾扬清在朋友圈发表观点认为,首先“对标OpenAI的公司有一波被其他大厂fomo(害怕错过)收购的机会”;其次“长线闭源寡头,开源还需要一段时间才能catch up”;最后,算法小厂“要不就算法上媲美OpenAI,要不就垂直领域深耕应用,要不就开源”,并预言“infra的需求继续会猛增”。 从投资角度来看,如果对标去年年初那一波A股的AI炒作风潮,算力和游戏是最亮眼的存在。 尤其值得关注的一点是,在Sora公布前,有消息称OpenAI首席执行官Sam Altman要筹资7万亿美元,来彻底重塑全球半导体行业格局。 7万亿美元是什么概念?这基本是全球半导体产业的全部江山。拿这个钱,Altman可以直接把英伟达、AMD、台积电、博通、ASML、Meta、三星、英特尔、高通等公司全部打包带走。 这是奥特曼要来拯救地球了 ? Altman在X上发帖表示,OpenAI认为“世界需要更多的AI基础设施,包括晶圆制造能力、能源、数据中心等,而人们目前计划建设得不够。”他补充说,“建设大规模的AI基础设施和一个具有韧性的供应链对经济竞争力至关重要”,而OpenAI将努力提供帮助。 对此,英伟达创始人黄仁勋回应道:看好全球AI数据中心在未来4-5年里将翻番,增长到2万亿美元的规模。在此期间,更高效、更低成本的芯片会持续出现,大规模投资变得不那么必要。 不可否认的一点是,大模型产品从文字、图片上升到视频,AI训练量的不断提升,对算力的需求也呈现指数级增长态势,“卖铲子”的公司依旧是第一受益人。 目前A股市场上跟AI相关的ETF产品较多,涉及AI主题、云计算主题、大数据主题、5G主题和通信主题。 (本文内容均为客观数据信息罗列,不构成任何投资建议)不过A股目前还没有算力主题ETF,但去年5月,华夏、富国、汇添富、博时等8家基金公司已经申报了中证算力基础设施主题ETF。 据中证指数官网内容显示,中证算力基础设施主题指数,从两市中选取业务涉及数据中心建设及运营,服务器或芯片生产,交换机、路由器、光模块等,通信设备制造等算力基础设施等上市公司,成分股合计50只。 从该指数的前十大权重股来看,第一大权重股是中际旭创,占比高达8.81%。第二大权重股中兴通讯的占比也有8.26%。海光信息和工业富联分别为第三、第四大权重股,占比分别为7.7%和6.73%。 除了AI上游端,AI终端的趋势也是确定的。去年那一波AI行情,资金扎堆游戏板块就是最好的例证,任何科技创新的最终目的都是为了消费服务,坚定看好在AI终端领域有布局的公司。 著名风险投资公司a16z近期发布他们对AI投资的最新观点,目前摘录部分观点,仅供读者参考:a16z预测AI技术再过10年发展,一定会诞生很多引领行业潮流的新公司,且大概率是toC产品。他们认为新科技将带来平权,让今天的奢侈品变成明天的日常用品。 a16z 的AI投资理念:① 消费者行为无法预测:在消费市场,成功取决于产品本身的“吸引力”和创始人的直觉,不取决于团队背景和洞察力。 ② 文化变迁与平台转型:在文化变迁和平台转型交汇点进行投资,找到能够利用或创造新消费者行为的产品。(文化变迁”指是消费者需求,行为,观念等变化) ② 伴侣 + 社交:人人都能拥有真正关注你、理解你的AI朋友、恋人或挑战者,你能参与创建属于你的个性化社区。 ③ 健康 + 个人成长:人人都将拥有一个由AI教师、医生、营养师、理财顾问组成的专家团队,帮你活出更好的人生。时刻关注、洞察你,发现需求,自动 “推送”解决方案。 推荐阅读 周鸿祎:Sora意味着AGI实现将从 10 年缩短到 1 年! *免责声明:本文章为作者独立观点,不代表i黑马立场。 扫描下方二维码 加入科技交流群 ↓↓↓ 黑马营27期重磅开启 加入我们,成为产业新力量 ↓↓↓ 联系我们转载开白或商务合作:15222191516 与主编交流沟通:chenfu3721i黑马,创业黑马旗下媒体,让创业者不再孤独。创 业黑马 媒体矩阵 推荐关注↓↓↓
-
AI 圈炸了!OpenAI Sora问世,60秒视频一镜到底,网友:颠覆整个行业
大数据文摘出品 AI圈炸了!OpenAI刚刚发布了一个新模型Sora,宣布视频生成领域的GPT-4 时刻到来! 这是OpenAI首款文本到视频的模型,但出道即王炸,Sora能够根据用户的一句话生成长达一分钟的视频,且视频流畅度和稳定性皆在水准之上。 Sora 的问世将视频制作的艺术推向了新的巅峰,其AI制作的视频展现出了复杂的摄影艺术、多元角色设定、逼真的情绪捕捉以及对物理规律的精确模拟。 据悉,这是在 OpenAI 之前的成就——图像创作神器 DALL-E 以及文本生成巨擘 GPT-3 和 GPT-4的基础上,进一步的创新与突破。 Sora 不仅能够在视频主体暂时离开镜头时保持故事线的流畅,还能确保视频内容的真实性和逻辑性,不让任何细节显得突兀或不自然。得益于其采用的Transformer架构,Sora 在处理视频生成的可扩展性上也远超以往任何模型。 以下是两个示例: Prompt: “A stylish woman walks down a Tokyo street filled with warm glowing neon and animated city signage. she wears a black leather jacket, a long red dress, and black boots, and carries a black purse. she wears sunglasses and red lipstick. she walks confidently and casually. the street is damp and reflective, creating a mirror effect of the colorful lights. many pedestrians walk about.” 提示:一位时尚女性走在充满温暖霓虹灯和动画城市标牌的东京街道上。她穿着黑色皮夹克、红色长裙和黑色靴子,拎着黑色钱包。她戴着太阳镜,涂着红色口红。她走路自信又随意。街道潮湿且反光,在彩色灯光的照射下形成镜面效果。许多行人走来走去。 Prompt: “Animated scene features a close-up of a short fluffy monster kneeling beside a melting red candle. the art style is 3d and realistic, with a…